Python에서 DB를 본격적으로 다루고 싶다면 DB API만으로는 한계가 있는데, 이에 Python DB tool 중 독자적인 SQLAlchemy에 대해 알아보도록 하자. python DB API에 대해서는 이전 글을 참고한다.
Overview #
SQLAlchemy 문서에서는 스스로를 The Database Toolkit for Python 라고 소개하고 있다.
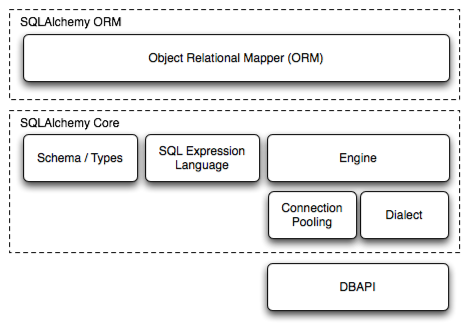
여러 DBMS에서 쿼리를 파이썬 함수로서 실행할 수 있게 해주며, orm도 다룰 수 있도록 지원하는 라이브러리라고 보면 될 것이다.
Core #
비교적 저수준의 레이어로, 여러 DBMS에 호환되도록 하는 쿼리 생성 및 실행, 트랜잭션 및 커넥션에 책임을 갖는 레이어로 이해하면 될 것 같다. 그림에 나와있다시피 core 레이어에는 dialect, connection pooling, engine 등이 존재한다. 오늘은 connection pooling까지 알아보자.
Dialect #
DBMS마다 실행을 위한 DB API(예: pymysql, sqlite3)가 다르다. SQLAlchemy는 이러한 DB API 위에서 추상화 계층을 제공하는 Dialect(방언, 사투리) 모듈을 제공한다. 이를 통해 우리는 SQLAlchemy + DB 드라이버 조합을 사용하여 DBMS가 변경되더라도 큰 코드 수정 없이 유지할 수 있다.
Dialect는 데이터 타입 변환, 트랜잭션 처리 등 DBMS별 차이를 보완하는 역할을 수행하여 sqlalchemy가 특정 DBMS와 소통할 수 있도록 도와준다고 볼 수 있다.
다음은 SQLAlchemy가 기본적으로 지원하는 Dialect와 드라이버의 조합을 표현한 예시이다.
- SQLite (
sqlite://) - PostgreSQL (
postgresql+psycopg2://) - MySQL / MariaDB (
mysql+pymysql://) - Oracle (
oracle+cx_oracle://) - Microsoft SQL Server (
mssql+pyodbc://)
또한, community에서 추가적인 Dialect를 제공하는 경우도 있으니, 위에 해당하지 않는 DBMS의 경우 찾아보도록 하자.
Connection Pooling #
connection pooling은 DB api의 스펙이 아니므로 파이썬 db driver가 제공하는 기능은 아니고, sqlalchemy에서 제공하는 기능이다.
connection pool(연결 풀)은 application에서 쿼리 실행마다 DB와의 connection(아마 TCP connection)을 맺고 끊는데 드는 비용을 아끼기 위해 커넥션을 일정 갯수만큼 갖고 있는 기법이다. DB 실행을 위해서는 커넥션이 필요할텐데 connection pool에 우선 접근하고, (없다면 새로운 connection 할당) 연결을 종료한다면 connection pool에 반납될 것이다.
SQLAlchemy는 이를 pool 모듈에서 제공하며 connect 함수가 connection pooling 기법을 이용한다. 보통은 뒤에 나올 engine 객체를 초기화할 때 파라미터를 통해 QueuePool을 컨트롤 할 수 있고 pool 모듈을 직접 다루진 않을 것이다.
connect() #
Pool 모듈에도 conect() 메서드가 제공되는데, 이는 connection 객체를 리턴하는 DB API의 connect와 다르니 짚고 넘어가자.
-
풀 정책 확인 후 커넥션 반환
- 사용하지 않는 커넥션이 있다면 반환한다
-
반환 불가하다면 새로운 커넥션 생성
- 새로운 커넥션 생성이 불가능한 경우 예외 발생
-
connection 객체 리턴
- 사용하는 db driver의 connection 객체를 리턴 (이제ㅂ터 해당 커넥션은 사용중으로 간주)
-
connection.close() 호출시, 풀에 커넥션 반환
- 해당 커넥션은 종료되지 않고 풀에 반환된다!!
이제 위에서 생성한 QueuePool로 connection pooling을 다뤄보자.
QueuePool 생성하기 #
한번 pymysql 드라이버를 통해 QueuePool 기능을 활용해보자. (queuepool은 알케미의 기본 풀 정책이다. async_engine을 사용하는 경우에는 AsyncAdaptedQueuePool이라고..)
from sqlalchemy.pool import QueuePool
import pymysql
# SA QueuePool 생성
pool = QueuePool(
creator=lambda: pymysql.connect(
host="localhost",
user="root",
password="yourpw",
database="test_db",
port=3306,
),
pool_size=5,
max_overflow=10,
timeout=30,
recycle=1800,
)
QueuePool 생성자의 파라미터들이 의미하는 것은 다음과 같다.
- creator : DB API에서 connection 객체를 반환하는 함수
- pool_size : 해당 풀에 담는 connection의 최대 개수 (default 5)
- max_overflow : pool_size를 넘었을 때, 추가 허용 connection 개수 (default 10)
- timeout : pool.connect()가 실행되었지만 pool에 남은 connection이 없을 때, 최대 기다릴 시간 (default 30)
- recycle : connect시, 장기 미사용 connection을 폐기하는 정책의 시간 기준 (default -1)
- use_lifo : FIFO(First In First Out) 대신 LIFO(Last In First Out) 전략으로 connection들을 관리할 지 여부
한번 생각해보자. 위에서 생성한 pool의 경우, 최대 connection은 몇개까지 가능할까?
15(5+10)개이다. 16번째 connectoin은 생성되지 않고 기존 connection이 close되길 기다릴 것이다.
connections = []
# Pool 크기를 초과하는 연결 시도
for i in range(15):
conn = pool.connect()
connections.append(conn)
print(f"Connection {i + 1} opened.")
15개까지는 생성된다. 15 초과로 loop 횟수를 변경해보면 30초(timeout)간 기다린 후 sqlalchemy.exc.TimeoutError: QueuePool limit of size 5 overflow 10 reached, connection timed out, timeout 30.00 (Background on this error at: https://sqlalche.me/e/20/3o7r) 라는 오류 메시지와 함께 TimeoutError가 발생할 것이다.
connect된 connection은 pool 입장에서는 사용중이므로 다음과 같이 close해줘야 한다.
# 연결 반납
for conn in connections:
conn.close()
print("Connection closed.")
15개의 커넥션이 종료되었다. (하지만 pool에 반납된 것이다) 이제 pool.connect()를 실행하면 다시 동작할 것이다.
필자의 경우에도, 연결을 제대로 반납하지 않아 TimeoutError를 마주한 적이 있었다. sqlalchemy engine에서 connect메서드를 통해 connection을 가져간다면, 항상 사용 후에 해당 connection을 close해주어 connection pool에 반납을 해주도록 하자!
추가로 커넥션 풀을 관리하며 알아두면 좋을 인자 몇개들을 알아보자.
recycle #
pool.connect() 로 connection pool로부터 유휴 커넥션을 가져올 때, 해당 connection이 사용하지 않은지 recycle초 이상되었다면 해당 연결을 닫고, 새로운 connection을 가져온다.
이는 application server 입장에서의 connection이 있더라도, DBMS단에서 connection을 닫아버렸을 수도 있기 때문이다. MySQL로 예시를 들면, wait_timeout이라는 변수가 있는데 유휴시간이 wait_timeout 이상이라면 MySQL입장에서 커넥션을 닫아버리는 경우가 있다. 참고
이외에도 여러가지 이유로 오랫동안 사용하지 않은 connection은 server~client 모두가 서로 연결되었다고 확신할 수 없기 때문에 recycle 필요하다. 위의 사례에서 보았듯, MySQL의 wait_timeout은 pool의 recycle보다 크도록 설정해야 할 것이다. 그래야 만료된 connection으로 요청하지 않을 수 있다.
pre_ping #
connection recycle을 하더라도 모종의 이유로 connection이 끊길 수 있다. 따라서, connect()시 select 1; 쿼리를 날려서 해당 커넥션이 유효한지 확인하고 유효하지 않다면 새로운 커넥션을 생성하는 pre_ping 옵션을 줄 수 있다. 가장 확실하지만 매 connection마다 추가로 쿼리를 날려야한다는 점에서 부담이 될 수 있다.
그치만 DBMS 자체가 다운된 경우에는 pre ping을 날려도 소용없고 오류가 발생할 것이다.
reset_on_return #
커넥션이 풀로 반환될 때,(conn.close()) 수행할 동작을 지정하는 인자이다.
- rollback : default. 해당 커넥션을 초기상태로 되돌린다.
- commit : 해당 connection에 커밋을 날린다. 만약 트랜잭션에 남아있는게 있고 autocommit = False인 경우, 커넥션이 종료되면서 커밋이 되는 건 일반적인 상황은 아닐 것 같다.
- None : 아무것도 하지 않는다. autocommit=True인 경우 해당 설정 통해 효율을 높일 수 있을 것 같긴 하다.
sqlalchemy에서는 pool 모듈을 직접 활용하는 경우는 적지만, 다음에 알아볼 engine 객체에서 pool prefix를 통해 설정이 가능하므로 주요 속성들을 알아두는 것이 좋다.
다음에는 core의 핵심인 engine 객체에 대해 알아보도록 하겠다.
화이팅 ~!