오늘은 SQLAlchemy의 핵심 컴포넌트 중 하나인 Engine에 대해 알아보도록 하겠다.
Engine #
Engine은 SQLAlchemy를 이용하여 DB와 소통을 위한 시작점이다. Alchemy에서 제시한 layer 중에서 core module에 해당한다.
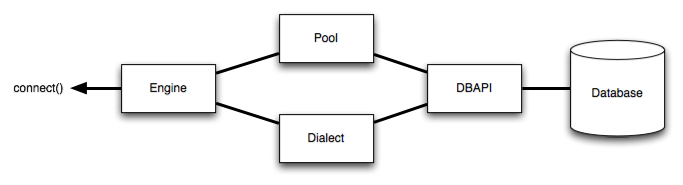
위의 그림처럼, 실제 DB와 통신하기 위한 DB API, 그 위에 존재하는 dialect와 connection pool의 기능을 하나로 제공하기 위한 것이 engine이라고 볼 수 있다. 사실상 engine은 dialect와 pool 모듈을 하나로 추상화한 모듈이다. 그렇기에 DB API를 통한 쿼리 호출시에 쓰인다기 보다는 그것을 위한 도구로 보통 DB당 하나의 엔진만 있으면 되므로, 생성과 삭제에 대해 초점을 맞추면 좋을 것 같다.
생성 (create_engine) #
Engine은 create_engine(url, **kwargs) 메서드를 통해 생성할 수 있다. (async의 경우, create_async_engine)
url은 문자열 혹은 URL 객체를 만들어서 넣어주면 되는데, 보통 문자열로 전달 시에 dialect+driver://username:password@host:port/database의 형식으로 작성한다.
주의할 점으로는, parsing에 기준이 되는 특수 문자열 \나 @가 있는 경우에는 적절히 변형하여 전달하거나, URL.create()를 통해 URL 객체를 직접 만들어줘야 한다. password에 특수문자열이 들어있는 경우 오류가 발생할 수 있다😅
dialect는 SQLAlchemy를 찾아보고, driver는 python db driver를 찾아보도록 하자. 이후 파라미터는 각 사용하는 DBMS의 접속 가능 정보를 입력하면 된다.
예시로, mysql을 위한 engine은 mysql+pymysql:// 혹은 mysql+mysqldb:// 등으로 시작할 것이다.
생성 != 커넥션 생성 #
engine을 생성했다고 DB 커넥션이 생성되는 것은 아니다. engine은 커넥션 풀을 관리하는 클래스이지, 커넥션 그 자체는 아니다. SQLAlchemy는 connection에 대한 클래스(connection)이 존재하는데, engine.connect()를 호출하면 커넥션 객체가 커넥션 풀에 전략에 맞게 생성된다.
우선, engine을 생성하는 예시를 interactive mode로 실행해보자. (echo 옵션으로 DB query에 대한 로그를 확인할 수 있다)
# test.py
engine = create_engine("mysql+pymysql://root:password@localhost/test_db", echo=True)
> python -i test.py
>>> (아무것도 출력되지 않는다)
>>> engine.connect()
2025-04-03 01:14:57,004 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2025-04-03 01:14:57,005 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-04-03 01:14:57,006 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2025-04-03 01:14:57,006 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-04-03 01:14:57,006 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2025-04-03 01:14:57,006 INFO sqlalchemy.engine.Engine [raw sql] {}
<sqlalchemy.engine.base.Connection object at 0x106d52c90>
connect()를 호출해야만 DB connection이 생성되어 리턴됨을 확인할 수 있다.
실제 connection이 생성되었는지는 mysql에서 select processlist; 쿼리를 날리면 현재 연결된 커넥션들을 확인할 수 있는데, engine.connect()를 수행하면 결과에 추가되는 것을 확인할 수 있다.
202 root 192.168.65.1:33765 test_db Sleep 1 NULL
203 root 192.168.65.1:31371 test_db Sleep 1 NULL
204 root 192.168.65.1:44481 test_db Sleep 1 NULL
205 root 192.168.65.1:51309 test_db Sleep 1 NULL
물론 engine.connect()를 여러번 수행한다고 해서 항상 connection이 생성되는 것은 아니고, connection pool 정책에 의해 생성될 것이다.
engine.pool.status() #
engine은 connection pool을 관리하는 pool 객체에 접근할 수 있고, status 메서드를 통해 현재 커넥션 풀의 상태를 확인할 수 있다.
> engine.pool.status()
> Pool size: 5 Connections in pool: 0 Current Overflow: -5 Current Checked out connections: 0
이제 create_engine의 주요 파라미터에 대해 알아보자.
주요 파라미터 #
이제 create_engine의 주요 파라미터에 대해 살펴보도록 하겠다. 이 파라미터들은 engine의 동작 방식을 조정하는 데 중요한 역할을 한다.
echo #
echo 파라미터는 SQLAlchemy가 실행하는 모든 SQL 문을 로그로 출력할지의 여부를 설정한다. 기본값은 False이며, True로 설정하면 실행되는 모든 쿼리와 그에 따른 결과를 콘솔에 출력하게 된다.
echo_pool #
echo_pool 파라미터는 커넥션 풀에 대한 로그를 남길지 여부를 결정한다. echo가 True일 경우에도 커넥션 풀의 활동이 로그에 출력되려면 이 값을 True로 설정해야 한다.
isolation_level #
isolation_level 파라미터는 트랜잭션의 격리 수준을 설정하는 데 사용된다. 여러 가지 격리 수준이 있으며, 대표적으로 AUTOCOMMIT, READ COMMITTED, REPEATABLE READ, SERIALIZABLE 등이 있다. 각 데이터베이스 관리 시스템(DBMS)에 따라서 지원하는 격리 수준이 다를 수 있으니, 적절히 설정하면 된다.
Pool 관련 파라미터 #
pool_ prefix인 설정들은 기본적으로 저번 포스트에서 다뤘던 Pool 클래스의 인자와 같다.
- max_overflow: 기본 풀 크기를 초과하여 얼마나 더 커넥션을 추가할 수 있는지를 설정한다.
- pool: 사용할 커넥션 풀의 유형을 지정한다. 기본값은
QueuePool이다. - pool_pre_ping: 커넥션 풀에서 반환되는 커넥션에 대해 유효성을 검사할지 여부를 설정한다.
True로 설정하면 커넥션 반환 전에 항상 체크를 수행한다. - pool_size: 기본 커넥션 풀의 크기를 설정하며, 기본값은 5이다.
- pool_recycle: 커넥션이 재활용되기 전에 유지되는 최대 시간을 설정한다. 이 시간을 초과하면 커넥션은 폐기되고 새로운 커넥션으로 교체된다.
- pool_timeout: 커넥션 풀에서 커넥션을 대기할 최대 시간을 초 단위로 설정하며, 기본값은 30초이다.
이제 Engine에서 제공하는 주요 메서드를 알아보자.
Engine.connect() #
Engine.connect() 메서드는 실제 데이터베이스와의 연결(connection)을 요청하는 메서드이다. 이 메서드를 호출하면 SQLAlchemy connection 객체가 반환되며, 이를 통해 데이터베이스 작업을 수행할 수 있다. 사용 후에는 close() 메서드를 호출하여 연결을 해제해야 한다.
connection = engine.connect()
try:
# 데이터베이스 작업
finally:
connection.close()
sqlalchemy의 connection 객체는 DB API의 connection을 감싼 객체이다. 만약 후자의 커넥션 객체의 접근하고 싶다면 connection.connection으로 가능하다.
Engine.begin() #
Engine.begin() 메서드는 트랜잭션을 시작할 때 사용되는 메서드이다. 이 메서드를 호출하면 connection 객체가 반환되고, 트랜잭션을 담당하는 context manager가 활성화되어, 모든 쿼리가 해당 트랜잭션 내에서 처리된다. context manager 진입시 BEGIN되고, 나가면서 COMMIT이 일어난다.
>>> with engine.begin() as conn:
... conn.execute(text("select 1"))
...
INFO:sqlalchemy.engine.Engine:BEGIN (implicit) # contextmanager enter
INFO:sqlalchemy.engine.Engine:select 1
INFO:sqlalchemy.engine.Engine:[generated in 0.00019s] {}
<sqlalchemy.engine.cursor.CursorResult object at 0x1029130e0>
INFO:sqlalchemy.engine.Engine:COMMIT # contextmanager exit
이렇게 함으로써 트랜잭션을 쉽게 관리할 수 있으며, 예외가 발생하는 경우에는 자동으로 롤백된다.
>>> with engine.begin() as conn:
... raise Exception()
...
INFO:sqlalchemy.engine.Engine:BEGIN (implicit)
INFO:sqlalchemy.engine.Engine:ROLLBACK
로그를 보면, BEGIN (implicit)을 수행하는데, 이는 실제 begin transaction 쿼리가 나가는 것은 아니라고 한다. 공식문서에는 다음과 같이 서술되어 있다.
You might have noticed the log line “BEGIN (implicit)” at the start of a transaction block. “implicit” here means that SQLAlchemy did not actually send any command to the database; it just considers this to be the start of the DBAPI’s implicit transaction. You can register event hooks to intercept this event, for example.
engine.begin()시, DB API에서 트랜잭션 시작으로 처리하고, 실제 BEGIN 쿼리는 별도의 쿼리 실행시 DBAPI가 자동으로 트랜잭션을 활성화하는 것으로 보인다.
connect()와 begin()은 모두 쿼리를 실행하기 위한 connection 객체를 얻을 수 있지만, begin은 트랜잭션에 대한 블록을 지정해준다는 점에서 차이가 있다.
Engine.dispose() #
Engine.dispose() 메서드는 모든 커넥션을 닫고 풀을 비우는 데 사용된다. 이를 통해 커넥션 풀이 사용하던 모든 커넥션을 안전하게 해제할 수 있다.
engine.dispose()
정리 #
SQLAlchemy engine은 커넥션 풀과 dialect를 다루기 위한 모듈이다. 따라서 보통 engine은 application 내에 DB 당 하나만 존재하는 것이 일반적이다. connection pooling을 담당하고(1), connection 객체를 통해 트랜잭션을 열고 쿼리를 실행(2)할 수 있지만, (2)에 대한 부분은 ORM을 지원하는 Session 객체를 통해 다루는 것이 일반적이다.
이번 글까지 sqlalchemy의 core module에 대해 알아보았다. 다음에는 SQLAlchemy에서 자주 접하게 될, 어찌보면 진짜 본체인 Session 객체에 대해 알아보도록 하겠다.
화이팅 😊